在今年的中国计算机大会(CNCC)上,参会者们不仅享受了一场科技盛宴,还意外地体验了一把由AI带来的便捷服务。大会举办地——横店圆明新园,以其宏大的规模和精美的建筑,给所有参会者留下了深刻印象。然而,园区之大,也让不少人感到腿酸脚痛。
面对这一挑战,有人突发奇想:能否让AI在横店帮我们点一杯咖啡?这个想法很快得到了实现。在CNCC现场,智谱公司发布了其最新研发的自主智能体AutoGLM,这一功能强大的手机操作助手和浏览器助手,让参会者们体验了一把“动口不动手”的便利。
通过简单的语音指令,AutoGLM就能打开美团,并根据指令点购咖啡,整个过程中,除了付款环节,完全不需要人的参与。这一功能不仅让参会者们惊叹不已,更让他们在现场成功喝上了由AI点购的咖啡。
智谱公司此次发布的GLM-4-Voice情感语音模型,更是让人眼前一亮。这一模型不仅拥有极高的响应速度和打断速度,还能准确感知和共鸣用户的情绪,其语音表达更是自然流畅,充满了“活人感”。在实测中,GLM-4-Voice不仅在英语陪练和日语练习上表现出色,还能轻松驾驭北京腔、台湾腔、东北腔和粤语等多种方言。
在CNCC的会场外,参会者们还带着AutoGLM游览了横店知名景点“秦王宫”,并让它以李白的身份即兴作诗一首。小智不负众望,创作了一首充满豪情壮志的诗句,赢得了大家的阵阵掌声。
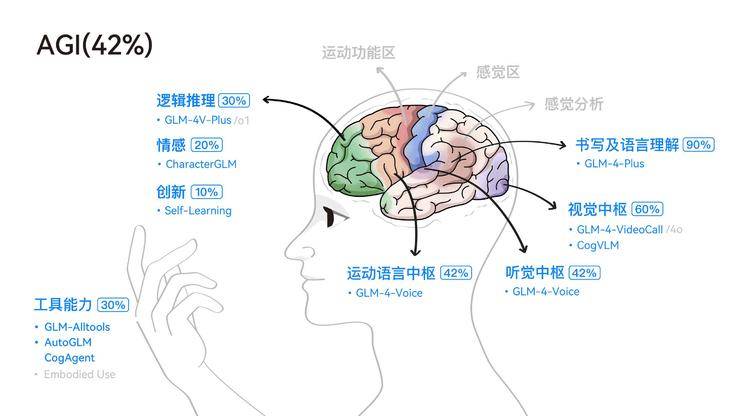
除了情感语音助手外,智谱公司还在CNCC上展示了其在AGI(通用人工智能)技术路径上的新思考。香港大学马毅教授在大会主题圆桌论坛中提到,人类智能有两个“原生大模型”:DNA和语言,它们都具备自我学习的能力。而当前的大模型虽然知识丰富,但在智能方面仍有不足。因此,要实现AGI,还需要在多模态、推理与自我学习等方面进行深入研究。

智谱公司的AutoGLM,正是其在工具能力上的新研究,也是其AGI实现路径之一。通过端到端的语音模型,GLM-4-Voice避免了传统级联方案中的信息损失和误差积累,实现了更高的建模上限。在预训练方面,智谱将Speech2Speech任务解耦合为Speech2Text和Text2Speech两个任务,并设计了两种预训练目标来适配这两种任务形式。
智谱公司还对AGI进行了深入的思考和探索。他们认为,尽管多模态是实现AGI的必经之路,但在多模态模型的研究中,仍需保持科学的怀疑和验证精神。目前,多模态研究仍存在诸多挑战,如不同模态之间的Gap、如何将不同模态结合起来等。
智谱公司的AGI路径是先聚焦文本大模型的能力提升,然后再逐步扩展到图像、视觉、语音等其他模态。他们不仅注重单一模态的单点能力提升,还注重双模态、多模态的结合。目前,智谱的AGI研究已经超越了追赶OpenAI的阶段,形成了一套自己的技术指南和路线图。

在CNCC现场,智谱公司还透露了其即将推出的生成视频模型CogVideoX的升级版本CogVideoX-Plus。这一新版本将支持60帧帧率、4K画质、10秒时长、任意比例图生视频,并大幅提升运动稳定性。这一消息无疑为参会者们带来了更多的期待和惊喜。
尽管距离AGI的实现还有很长的路要走,但智谱公司已经在这条路上迈出了坚实的步伐。他们的研究和探索不仅为AGI的发展提供了新的思路和方向,也为人工智能的未来发展注入了更多的活力和可能。